| |
Front Page |

| |

|
Using a Specialized Corpus to Improve Translation Qualityby Michael Wilkinson | ||
|
1 Corpora and corpus analysis tools
Corpus analysis tools enable users to investigate and manipulate the information contained within a corpus in a variety of ways. For example, most corpus analysis packages comprise a "concordancer", which will find all the occurrences of a search word, or search pattern, and display them in the centre of your screen, together with a span of co-text to the left and right, as in Figure 1.
Figure 1: Display of some of the concordance lines generated by WordSmith Tools version 4 for the search pattern eat* The display shown in Figure 1 is known as a Key Word In Context (KWIC) display. You can manipulate the order of the concordance lines: for example if your search word is a noun, you can ask the concordancer to sort the words immediately preceding the search word in alphabetical order, which may help you to find suitable adjectives that collocate with the search word. By double-clicking on a line, you can view it in its full context. Consulting printed "parallel" texts in the target language (TL)--in order, for example, to search for terminology or look for idiomatic phraseology--is of course something that translators are very familiar with. Consulting digitalized corpora by means of corpus analysis tools enables them to exploit large quantities of text far more rapidly and systematically.
2 Corpora in Translator Education In recent years there have been frequent recommendations by researchers and trainers in the field of translation studies to integrate the analysis of corpora into translator education. For example: "The methodology involved in making corpora and extracting terminology should be part of the teaching curriculum--not an optional extra--particularly given the pressure on translators to use computer-assisted tools." (Maia, 2003, p 52). "The knowledge of how to compile and use corpora is an essential part of modern translational competence, and should therefore be dealt with in the training of prospective professional translators." (Varantola, 2003, p 56). However, although corpus analysis tools have been extensively used for research purposes, it seems that, at least in translator education in Finland, the systematic use of such tools as actual translation aids has until now been rather neglected. It also seems that electronic corpora are not used widely by practising translators either, probably because they have not been exposed to the potential of corpus analysis tools during their own education and probably because of the unavailability of ready-made special-field corpora. Thus Jääskeläinen and Mauranen (2004, p 53) propose that courses on how to compile and use corpora should not only be integrated into translator training at the undergraduate level but also be offered as continuing education to practising translators. With this in mind, I began compiling a corpus of English-language tourism brochures in spring 2004, with the aim of using it to teach students how the competent use of electronic text corpora in conjunction with corpus analysis tools can help both the trainee translator and the professional translator to become better language service providers by enhancing both the quality of their work and their productivity, particularly when translating special field texts into a foreign language. (Many translators of non-literary texts in Finland frequently translate into their L2).
3 The Tourism Corpus There were a number of reasons for deciding to compile a TL-corpus of tourist brochures. Firstly, there is a high demand in Finland for tourism texts to be translated from Finnish into English, not only for various kinds of brochures but also for websites. Secondly, I myself have extensive experience in this field, having done a large amount of language checking for various professional translators as well as a certain amount of translating of tourism texts from Finnish into English. Thirdly, many printed tourist brochures also appear in PDF format on their owners' websites, and thus are relatively easy to convert into the plain text format required by many corpus analysis tools. And last but certainly not least, students seem to be attracted to this field--perhaps because there is a certain amount of glamour attached to travel and tourism, and perhaps also because the concepts are relatively easy for even the non-expert to understand compared with many other special fields. Nevertheless, translating tourist brochures can appear at first sight to be deceptively easy. For example capturing the right style, conforming to conventions of the target language and culture, and finding a consistent and logical strategy for translating names of places, resorts and establishments as well as for translating culture-specific terms are just a few of the difficulties that face the translator. In Finland, another problem is that although the source texts of some brochures are written with a foreign audience in mind, more often than not they are written first for the Finnish audience and it is this text that serves as the basis for the foreign language versions. The content is not necessarily geared towards a foreign audience, and thus there are, for example, frequent allusions to information that will be implicitly understood by the Finnish audience but not by the foreign audience. The texts of the Tourism Corpus were mainly derived from tourist brochures that appear on the Internet in PDF format. In many cases, converting these into plain text format was quite straight-forward, though in most cases careful post-editing needed to be done, since headings, and in some cases even complete paragraphs, frequently tended to switch positions in the conversion process. Usually, the more sophisticated and attractive the brochure, the trickier it was to convert into text format. By September 2004, with the help of a student assistant, I had compiled a corpus amounting to 670,000 words. There are various types of corpora and various ways of classifying them. The Tourism Corpus could be described as being an untagged monolingual target-language corpus. It contains mainly texts from brochures from the British Isles and from North America, especially Canada. When compiling the corpus, a major reason for including Canadian brochures was that they contain descriptions of activities that are often featured in Finnish source texts--e.g. snowshoe treks, skiing, snowmobile trips, wilderness adventures--which are rarely mentioned in British brochures. The file names have been labelled with one of the following codes: BI, CA, US, so that the user can immediately identify whether a concordance line is from the British Isles, Canada, or the United States, as illustrated in Figure 1.
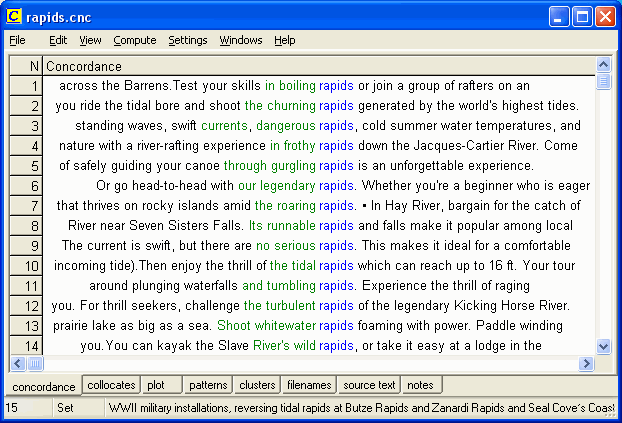
4 Exploiting the Tourism Corpus During the 2004-2005 academic year, I integrated corpus exploitation into my translation courses. Students received instruction in using the corpus analysis package WordSmith Tools (Scott, 2004), were taught various strategies for exploiting corpora when translating, and were given tourist brochure texts as translation assignments from Finnish into English. Examples are given below illustrating ways in which students have been able to exploit the Tourism Corpus in order to improve the quality of their translations. 4.1 Collocation The corpus has proved very useful for finding information about collocates, especially adjectives that collocate with nouns. For example, when translating sentences containing the noun rapids, the KWIC display provides a rich menu of adjectives to choose from, as illustrated in Figure 2.
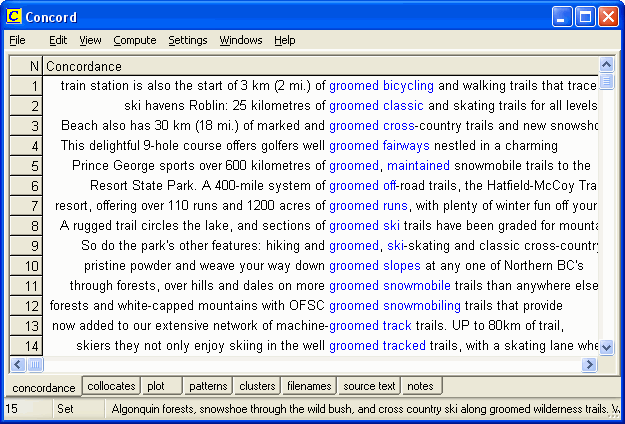
Figure 2: Display of some of the concordance lines generated by WordSmith Tools for the search word rapids When searching for collocates, the corpus often leads to somewhat unexpected discoveries. For example when looking for translation equivalents for hoidettu or kunnostettu when referring to cross-country ski trails, traditional resources suggest, for example, conditioned, maintained, restored and reconditioned as possible translation candidates. However, of the 1000-plus concordance lines generated by the search word trails, none of the above adjectives appear immediately to the left of the search word, while there are over 40 occurrences of the adjective groomed. Native speakers, especially North Americans, will probably be familiar with this term. However, most novice translators, and even those professional translators that have little experience in translating tourism texts, are not usually familiar with this adjective. A new concordance with groomed as the search word generates 128 hits, and provides evidence of, for example, groomed bicycle and walking trails, groomed classic and skating trails, groomed cross-country ski trails, groomed fairways, groomed off-road trails, groomed runs, groomed slopes, and groomed wilderness trails, as illustrated in Figure 3.
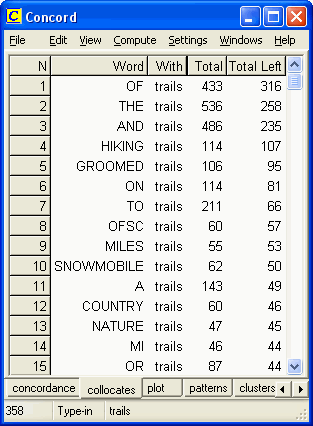
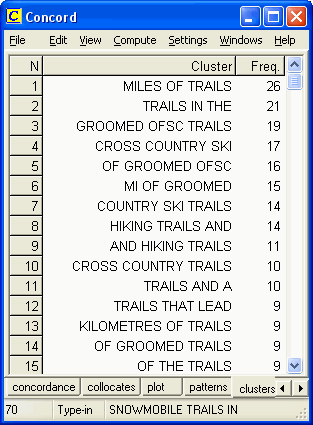
Figure 3: Display of some of the concordance lines generated by WordSmith Tools for the search word groomed However, even the seasoned concordance user may "miss" the 40-plus occurrences of groomed when scrolling through the 1000-plus hits for trails. Therefore, when a search word generates a large number of concordance lines, students are taught to turn to the collocates display and the clusters display. For example, Figure 4 shows the words that occur most frequently within a span of five words to the left of trails, while Figure 5 shows the most common 3-word clusters containing trails. Each of these displays helps to highlight the frequent co-occurrence of groomed and trails.
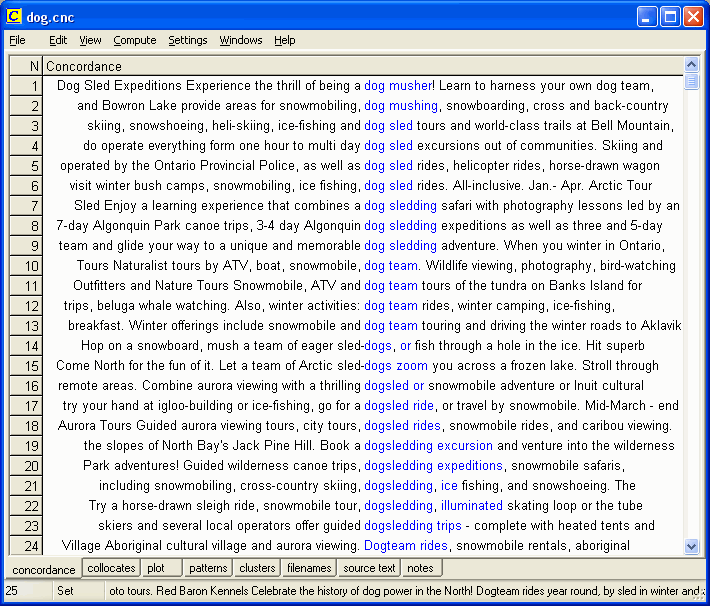
4.2 Finding and choosing between terms When deciding on a translation equivalent for a specific term or phrase, the corpus has been of great help in verifying or rejecting decisions based on other tools such as dictionaries and the Internet. An example of this is the Finnish term koiravaljakkoajelu. After hunting through traditional translation aids, student translators came up with the terms dog sled, dog sledge & dog sleigh, each of which is also often written with hyphens or as one word. The corpus helps in deciding on which of these alternatives to use. Figure 6 illustrates some of the concordance lines generated for the search pattern dog*. The original KWIC display contained 22 hits for dog sled, 27 hits for dogsled, and 6 hits for dog-sled, with no hits at all for dog sledge or dog sleigh or variations thereof. Moreover there were 68 hits for dogsledding, often written also as two words. The display also shows that adventure, excursion, ride, trip, and tour are amongst the nouns that collocate with dog sled.
Figure 6: Display of some of the concordance lines generated by WordSmith Tools for the search word dog*
Researchers such as Bernardini (2000, 2001) and Varantola (2003) have pointed out that corpora allow unpredictable, incidental learning: the user may notice and explore unknown or unfamiliar uses in a concordance and go off at a tangent to follow them up. Bowker & Pearson (2002, pp 200-202) show how creative search techniques, for example concordancing with contextually-relevant search words, can increase the likelihood of "accidentally" finding relevant information. As shown earlier, a search of the Tourism Corpus for trails led to the serendipitous discovery of the adjective groomed. The KWIC display in Figure 6 provides further examples of the kind of previously "unknown" information the translator might acquire when browsing through a KWIC display. This information may be relevant to the translation assignment at hand, or may come in handy for future assignments. Lines 1, 2 & 14 contain references to dog musher and dog mushing that may warrant further consideration; lines 6, 17 & 21 refer to ice-fishing, while line 14 encourages the tourist to fish through a hole in the ice--two possible translations for the Finnish term pilkkiminen; lines 10 & 11 mention ATV tours, lines 18 & 24 aurora viewing, line 21 snowshoeing, and line 22 illuminated skating loop, all of which may lead to further exploration by viewing in fuller context or by entering new search patterns. For example a search for ATV, will quickly reveal that this is a widely used abbreviation for All Terrain Vehicle--a possible translation candidate for mönkijä, a Finnish term that is difficult to find an equivalent for using traditional resources. 4.4 Language chunks Gavioli & Zanettin (1997) point out that a corpus acts as a continual source of additional raw material and consider that the greatest benefit of using TL corpora is that they can suggest multi-word "chunks" that students are able to use to produce texts that sound more natural in the target language. According to Gavioli & Zanettin, achieving such "naturalness" is probably the greatest benefit of using corpora in translation, particularly into the foreign language, where naturalness is more difficult to achieve.
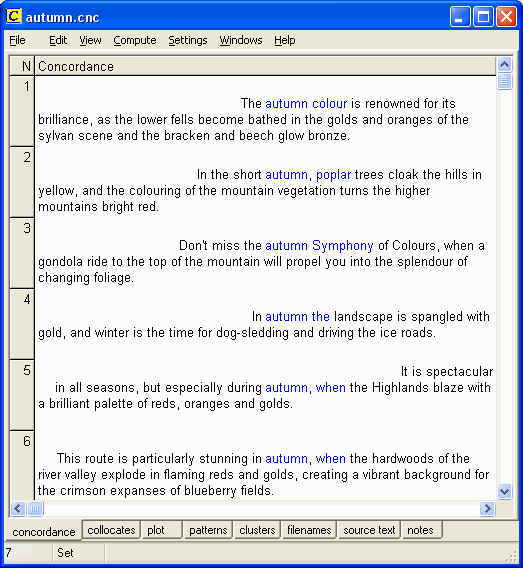
Finnish tourist brochures often contain references to ruska-aika, the period in autumn when the leaves change colour leading to breathtakingly beautiful landscapes. The translator may decide that the concept of ruska contains implicit information that needs to be expressed more explicitly for a foreign audience, and thus some sort of description is necessary. Figure 7 shows some of the concordance lines produced by a search for autumn. Words and phrases could be extracted from them and incorporated into the translator's own description.
Figure 7: Display of some of the concordance lines generated by WordSmith Tools for the search word autumn
If one had searched for fall, the American synonym for autumn, one would also have found references to the fall foliage season, brilliant foliage in fall and stunning fall foliage.
5 Words of Warning Some researchers, e.g. Ball (1997), have warned that the use of electronic text may tempt the analyst to seek only that which is easy to find--you notice only what you get back; you will not notice what you did not find. However the experience that I have had when integrating corpora analysis into translation courses suggests that creative searching is likely to result in a wealth of discoveries and answers to questions that the translator did not even think of asking in the first place. "Corpora are by nature conservative, in that they tend to highlight habitual usage, thus reinforcing existing patterns, i.e. if translators continually consult corpora to ensure the validity or existence of collocations, turns of phrase etc. the consequent recycling of previous utterances may contribute to the language becoming increasingly flat and conventional." (Stewart, 2000). However the reverse may be true--the KWIC often offers a large menu of alternative collocations and phrases, and thus can encourage novice translators to be more daring and more creative in their choices. Indeed, a general comment amongst the students in a workshop experiment conducted by Varantola was that corpus evidence makes it easier for translators to take radical decisions: "This evidence helps translators be less bound to the source material and feel much more confident when deviating from the way things are expressed in the source material if they feel that the changes are justified." (Varantola, 2003, p 67). The danger of excessive recycling is probably greater in regard to Translation Memory tools, which encourages translators to resort to past solutions, and thus may make them reluctant to seek new, creative solutions, and may also reduce their awareness of neologisms.
6 Future plans The intention is that the Tourism Corpus is an open corpus, i.e. texts will be constantly added (and some texts may be removed) to reflect the fact that concepts and terms within the field are constantly evolving. Since ready-made specialised electronic text corpora are few and far between, the translator needs to learn to construct such corpora. In the spring of 2005 I designed an interactive web-course that not only provides practice in using various corpus analysis tools but also includes guidelines on the technical and legal aspects of corpus compilation. The web-course will be available to students of Savonlinna School of Translation Studies during the 2005-2006 academic year.
References Ball, Catherine (1997). "Concordances and Corpora" (on-line tutorial), http://www.georgetown.edu/faculty/ballc/corpora/tutorial1.html (consulted 9 June, 2005). Bernardini, Silvia (2000). "Systematising serendipity: Proposals for concordancing large corpora with language learners." In Lou Burnard and Tony McEnery (eds) Rethinking language pedagogy from a corpus perspective: Papers from the third international conference on teaching and language corpora. Frankfurt am Main: Peter Lang 183-190. Bernardini, Silvia (2001). "Spoilt for choice': A learner explores general language corpora". In Guy Aston(ed) Learning with corpora. Houston (TX): Athelstan 220-249. Bowker, Lynne & Jennifer Pearson (2002). "Working with Specialize Language: a practical guide to using corpora". London: Routledge. Friedbichler, Ingrid & Michael (1997). "The Potential of Domain-Specific Target-Language Corpora for the Translator's Workbench". Paper presented at the first international conference on Corpus Use and Learning to Translate, Bertinoro, 14-15 November 1997. Gavioli, Laura & Federico Zanettin (1997). "Comparable corpora and translation: a pedagogic perspective". Paper presented at the first international conference on Corpus Use and Learning to Translate, Bertinoro, 14-15 November 1997. Jääskeläinen, Riitta & Anna Mauranen (2004). "Translators at work: a case study of electronic tools used by translators in industry" In Geoff Barnbrook, Pernilla Danielsson and Michaela Mahlberg (eds.) Meaningful Texts: The Extraction of Semantic Information from Monolingual and Multilingual Corpora. Continuum International Publishing Group Ltd 49-53. Maia, Belinda (2003). "Some languages are more equal than others. Training translators in terminology and information retrieval using comparable and parallel corpora". In Federico Zanettin, Silvia Bernardini and Dominic Stewart (eds.) Corpora in Translator Education. Manchester: St Jerome 43-53. Scott, Mike (2004). WordSmith Tools version 4, Oxford University Press. Stewart, Dominic (2000). "Supplying Native Speaker Intuitions or Normalising Translation? Translating into English as a foreign language with the British National Corpus". From the abstract of a paper in the provisional programme of the UMIST/UCL Conference: Research Models in Translation Studies, Manchester, 28-30 April 2000. Varantola, Krista (2003). "Translators and Disposable Corpora". In Federico Zanettin, Silvia Bernardini and Dominic Stewart (eds.) Corpora in Translator Education Manchester: St Jerome, pp 55-70. |
||
|
|
 n the context of Computer Aided Translation Technology (CATT), a corpus can be described as a large collection of texts in electronic format. Electronic corpora can be "enriched" by, for example, annotating them with part-of-speech (POS) tagging, and this is especially useful in order to enable researchers to carry out sophisticated linguistic investigations. But, as I hope to show in the following, even an untagged corpus of texts (so-called "raw" text) can be a useful performance-enhancing tool in translating; for example it can be of great help in confirming intuitive decisions, in verifying or rejecting decisions based on other tools such as dictionaries, in obtaining information about collocates (words that typically co-occur), in reinforcing knowledge of normal target language patterns, and in learning how to use new expressions.
n the context of Computer Aided Translation Technology (CATT), a corpus can be described as a large collection of texts in electronic format. Electronic corpora can be "enriched" by, for example, annotating them with part-of-speech (POS) tagging, and this is especially useful in order to enable researchers to carry out sophisticated linguistic investigations. But, as I hope to show in the following, even an untagged corpus of texts (so-called "raw" text) can be a useful performance-enhancing tool in translating; for example it can be of great help in confirming intuitive decisions, in verifying or rejecting decisions based on other tools such as dictionaries, in obtaining information about collocates (words that typically co-occur), in reinforcing knowledge of normal target language patterns, and in learning how to use new expressions.