|
Front Page

| |

|
Overcoming the Digital Dividethrough Machine Translationby Preeti DubeyDept of Computer Sciences & IT, University of Jammu, Jammu, India | |
|
Abstract The digital divide is the gap between those with regular; effective access to digital technologies, in particular the Internet, and those without. Researchers have quoted many factors responsible for the digital divide, including: low internet access, low literacy rate, geographical locations, economic conditions, and language barrier. Efforts are being made to provide Internet access by expanding the internet cafés for public use. Communication costs have dropped and many other negative factors have been eliminated or alleviated. One obstacle in bridging the digital divide is the language of the web content. In this paper the authors stress the divide created due to the language barrier. Over 80% of websites are in English despite the fact that less than one in ten people in the world speak that language, which, is one major reason for the digital divide. The majority of Indians, especially those living in rural areas are not proficient in English, which affects both acquisition and dissemination of knowledge by rural communities. This is known as the language barrier, and can be alleviated by machine translation (MT). Machine translation (MT) is the use of computer software to translate text or speech from one natural language into another. Translation of English to Indian languages will provide language-independent interface to the knowledge world and include those excluded from the Web world due to their insufficient understanding of English. This paper is a study of machine translation methods and the various Indian Machine Translation Systems (MTS). In the future, the authors' will focus on developing a MTS to convert the national language (Hindi) to the local language (Dogri) to overcome the language barrier and hence narrowing the Digital Divide. Keywords: Digital Divide, Machine Translation, Lexicon, Morphology
Machine translation (MT) is the use of computer software to translate text or speech from one natural language into another. Like translation done by humans, MT does not simply involve substituting words in one language for another, but the application of complex linguistic knowledge: morphology (how words are built from smaller units of meaning), syntax (grammar), semantics (meaning), and understanding of concepts such as ambiguity. The translation process may be stated as:
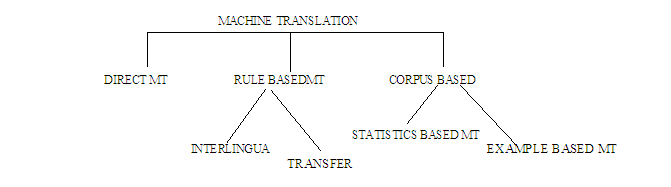
To decode the meaning of the source text in its entirety, the translator must interpret and analyze all the features of the text. This process requires in-depth knowledge of the grammar, semantics, syntax etc of the source language and the same in-depth knowledge is required for re-encoding the meaning in the target language. In general, a machine translation system contains a source language morphological analyzer, a source language parser, translator, a target language morphological analyzer, a target language parser, and several lexical dictionaries. The source language morphological analyzer analyzes a source language word and provides morphological information. The source language parser is a syntax analyzer that analyzes the source language sentences. A translator is used to translate a source language word into the target language. The target language morphological analyzer works as a generator and generates appropriate target language words for given grammatical information. Also the target language parser works as a composer and composes suitable target language sentences. An MT system needs a minimum of three dictionaries such as the source language dictionary, the bilingual dictionary and the target language dictionary. The source language morphological analyzer needs a source language dictionary for morphological analysis. A bilingual dictionary is used by the translator to translate the source language into the target language; and the target language Morphological generator uses the target language dictionary to generate target language words. Machine Translation (MT) Methods Machine Translation is an important sub-discipline of the wider field of artificial intelligence (AI). Some approaches to machine translation are:
At present, there are a variety of machine translation systems such as Anusaaraka, Mantra, Angalahindi, etc. Some of them have been discussed below: Anusaaraka is a popular machine-aided translation system for Indian languages that makes text in one Indian language accessible in another Indian language. This system uses the Paninian Grammar (PG) model for its language analysis. The Anusaaraka project has been developed to translate Punjabi, Bengali, Telugu, Kannada and Marathi languages into Hindi. The approach and the lexicon are general. The output generated is understandable but not grammatically correct. The system has been applied mainly to children's stories. MANTRA(Machine Assisted Translation Tool) is one of the Web-enabled machine translation systems, which translates the English text into Hindi in a specified domain of personal administration, specifically gazette notifications, office orders, office memorandums, and circulars. It uses Tree Adjoining Grammar (TAG) for Parsing and Generation and a bottom-up parsing algorithm to speed up the parser and online word addition and grammar updating facilities. Angalahindi is web-based English to Hindi machine-aided translation system. It is a version of Anglabharati. It is specifically designed for translating English to Indian languages. English is a SVO (subject-verb-object) language while Indian languages are SOV (subject-object-verb) and have a relatively free word order. Instead of designing translators for English to each Indian language, Anglabharti uses a pseudo-interlingua approach. It analyses English only once and creates an intermediate structure called PLIL (Pseudo Lingua for Indian Languages).The PLIL structure is then converted to each Indian language through a process of text-generation. It is used for translation from English to all Indian languages. UNL-based English-Hindi machine translation system: The Universal Networking Language (UNL) is an international project of the United Nations University, with an aim to create an Interlingua for all major human languages. IIT Bombay is the Indian participant in UNL, and it is working on MT systems between English, Hindi and Marathi using the UNL formalism. This uses an Interlingua approach--the source language is converted into UNL using an 'enconverter', and then converted into the target language using a 'deconverter'. Shiva and Shakti machine translation: The Shiva and Shakti are the two Machine Translation systems from English to Hindi and have been developed jointly by Carnegie Mellon University USA, International Institute of Information Technology, Hyderabad, and and Indian Institute of Science, Bangalore, India. The system Shiva is an Example-based and the system Shakti is working for three target languages like Hindi, Marathi and Telgu. Shakti MTS has been designed to produce machine translation systems for new languages rapidly. The Shakti system combines rule-based approach with statistical approach whereas Shiva is an Example-Based machine translation system. Hindi to Punjabi machine translation system: The Hindi to Punjabi Machine translation System was developed by Goyal and Lehal (2010) at Punjabi University Patiala in the year 2009. This system is based on direct word-for-word translation approach. This system consists of modules like pre-processing, word-for-word translation using a Hindi-Punjabi lexicon, morphological analysis, word sense disambiguation, transliteration, and post-processing. The system has reported 95% accuracy.
The Internet may become the main medium of communication in the future.As the internet becomes the increasing vital tool in our society and technology provides increasing options to citizens to conduct their daily activities online such as learning, shopping, payment of bills, registration of licensees etc.; people who lack access to or are unable to utilize these tools, are at a growing disadvantage and will eventually be unable to function in this increasingly information-based society. Therefore there is an urgent need to bridge the digital divide and provide digital opportunities to those excluded from the Web. Machine Translation enables localization of information, and is very important in a linguistically diverse country like India. Machine translation has enabled communication in the users' native language; thus removing the language barrier among people and reducing the digital divide. Many languages have been translated, yet a lot many need translation.
A number of Machine Translation systems between Indian and non-Indian languages have already been developed; but there is still no Machine Translation system for Hindi to Dogri (the regional language of Jammu). In the future. the authors will focus on developing such a MT system so that Dogri can be made a part of the Web.
[1] Keniston Kenneth. (2004). "Introduction: The Four Digital Divides". In K. Keniston and D. Kumar (Eds.) IT Experience in India. Delhi: Sage Publishers [2] Mário Rodrigo Canazza, "Global Effort on Bridging the Digital Divide and the Role of ICT Standardization", in Proc IEEE Conf on Innovations for Digital Inclusions on Aug 31-Sept 1, 2009, page(s): 1-7 [3] Om Vikas, "Multilingualism for Cultural Diversity and Universal Access in Cyberspace: an Asian Perspective", UNESCO, 6-7 May 2005. [5] http://iamai.in/PRelease_detail.aspx?nid=1754&NMonth=1&NYear=2009 [6] N. Balakrishnan, "Information and communication technologies and the digital divide in the Third World countries", Current Science, Vol. 81, No. 8, 25 October, 2001 [7] Mark Warschauer, "Technology and Social Inclusion: Rethinking the Digital Divide" (Cambridge, MA: MIT Press, 2003), 274 pp. [8] Pandey et al, "From Digital Divide to Digital Opportunity", Proceedings of IEEE Region10 Conference, 19-21 Nov. 2008, page(s): 1 -6. [9] Budditha Hettige et al, "Web-based English-Sinhala translator in action", in Proc IEEE Conf on Information and Automation Sustainability, on 12-14 Dec 2008 on pages 80-85. [10] Vishal Goyal and Gurpreet Singh Lehal, "Web Based Hindi to PunjabiMachine Translation System", Journal of Emerging Technologies in Web Intelligence, Vol. 2, No. 2, May 2010, pg(s):148-151. [11] Anusaraka: A Device to Overcome the Language Barrier, V.N. Narayana, Ph.D. thesis, Dept. of CSE, I.I.T. Kanpur, 1994. [12] Bharati, A., R. Moona, P. Reddy, B. Sankar and D.M. Sharma et al., 2003. Machine translation: The Shakti approach. Proceedings of the 19th International Conference on Natural Language Processing, Dec. 2003, India, pp: 1-7.
|
|
|
|
 n the past few years, Internet usage worldwide has soared. The Internet has evolved to be the gateway for almost all information that circulates around the world. People have started using the Internet not only for entertainment purposes, but also for knowledge, culture, business, and socialization, making way for a period of great economic prosperity and development in the beginning of the 21st century for almost every nation on the planet. The impact of the Internet on world economic prosperity in the last ten years is so evident that the current economic cycle has been labeled as the "Internet Economy." The widespread use of the Internet has created a divide between those who have access to it and those who do not. One formidable obstacle to the diffusion of Information and Communication Technology (ICT) is language. There is a self-perpetuating cultural hegemony associated with ICTs (Keniston, 2002). By the year 2000, only 20% of all Web sites in the world were in languages other than English, and most of these were in Japanese, German, French, Spanish, Portuguese, and Chinese. But in the larger regions of Africa, India, and south Asia, less than ten percent of people are English-literate while the rest, more than two billion, speak languages that are sparsely represented on the Web. Because of the language barrier the majority of people in these regions have little use for computers. Those who do not use computers have little means to drive market demands for computer applications in their language. National excellence in the millennium will be determined by the extent to which the Information Technology can deliver its potential in local languages. In a country like India, it is crucial to the growth of society and to bridging the Digital Divide that communication overcome the language barrier.
n the past few years, Internet usage worldwide has soared. The Internet has evolved to be the gateway for almost all information that circulates around the world. People have started using the Internet not only for entertainment purposes, but also for knowledge, culture, business, and socialization, making way for a period of great economic prosperity and development in the beginning of the 21st century for almost every nation on the planet. The impact of the Internet on world economic prosperity in the last ten years is so evident that the current economic cycle has been labeled as the "Internet Economy." The widespread use of the Internet has created a divide between those who have access to it and those who do not. One formidable obstacle to the diffusion of Information and Communication Technology (ICT) is language. There is a self-perpetuating cultural hegemony associated with ICTs (Keniston, 2002). By the year 2000, only 20% of all Web sites in the world were in languages other than English, and most of these were in Japanese, German, French, Spanish, Portuguese, and Chinese. But in the larger regions of Africa, India, and south Asia, less than ten percent of people are English-literate while the rest, more than two billion, speak languages that are sparsely represented on the Web. Because of the language barrier the majority of people in these regions have little use for computers. Those who do not use computers have little means to drive market demands for computer applications in their language. National excellence in the millennium will be determined by the extent to which the Information Technology can deliver its potential in local languages. In a country like India, it is crucial to the growth of society and to bridging the Digital Divide that communication overcome the language barrier.