| |
| |
Front Page |


| |

|
Quick Corpora CompilingUsing Web as Corpusby Michael Wilkinson |
|
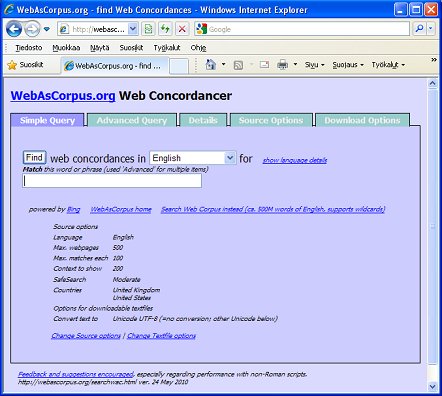
The Web as Corpus (WaC) website, launched by Bill Fletcher in 2007, includes a user-friendly freeware concordancer that goes a long way to solving this problem. In the following I provide a simple guide on how to use the tool. Go to the WaC site at: http://webascorpus.org/ Click on Web Concordancer, which will take you to: http://webascorpus.org/searchwac.html, as shown in Figure 1. Select the language you want in "Find web concordances in xxxxx"
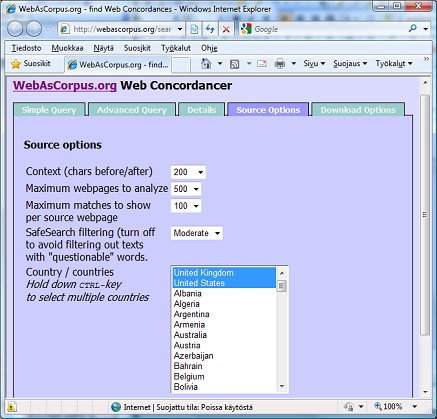
Figure 1 Click on the "Source Options" Tab and you will get the view shown in Figure 2:
Figure 2 You can now select things like the amount of context to show, how many web pages to analyse and maximum matches to show per page as well as "source" countries. It's perhaps best to try these alternatives out for yourself to see how they affect your results. In the "Details" section of the tool, Fletcher has various tips about this, such as the following:
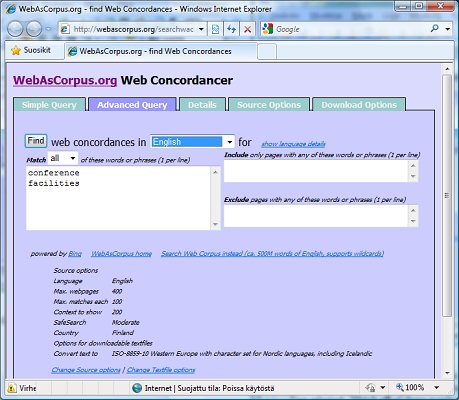
Now click on the "Advanced Query" tab. You need to feed in enough words to make sure that the pages found are restricted to the special field you have in mind. So recently, when I was translating a text about a multi-function conference centre in eastern Finland from Finnish into English, I tried the query shown in Figure 3.
Figure 3 Notice that you must enter each word or phrase on separate lines. If I'd entered "conference facilities" on the same line, this would have restricted the search excessively. But notice also that I've selected "Match all of these words" - if I'd selected "Match any" I would have got too many irrelevant "hits" (e.g. all kinds of facilities that are unrelated to conferences). You need to enter enough words to limit the field, but not so many as to excessively restrict the finds. Unfortunately you can't use wildcards in your search words. The Include / Exclude boxes also help you to focus your search. When I first started using this tool, I compiled a corpus to help me with a translation about seals in the lakes of eastern Finland. My failure to use the exclude-box resulted in a tremendous amount of unwanted material relating to, for example, mechanical devices that prevent leakage, the special operations forces of the US Navy, contract law, emblems, and a well-known British singer. I should have read Fletcher's tips about this:
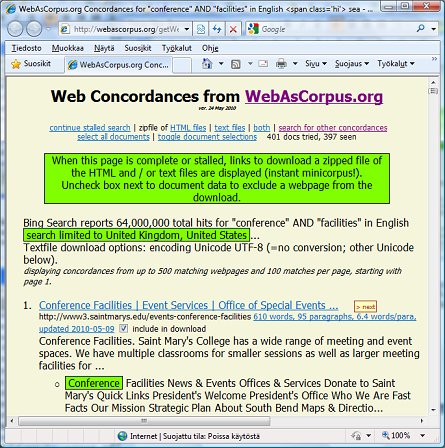
Now press the "Find" button in the top left of the Advance Query window. The Web Concordancer occasionally stalls before it reaches the specified number of hits. This is apparently due to a delayed response from Bing (the search engine it uses) or overload on WaC's server. Clicking the "continue stalled search" link usually succeeds in remedying this.
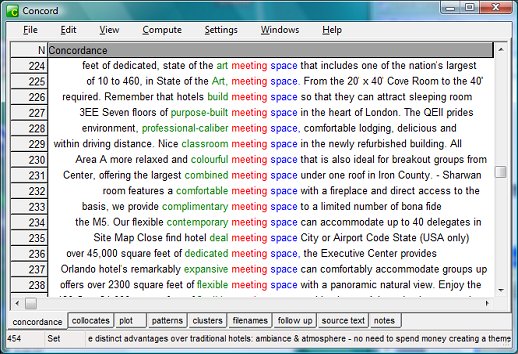
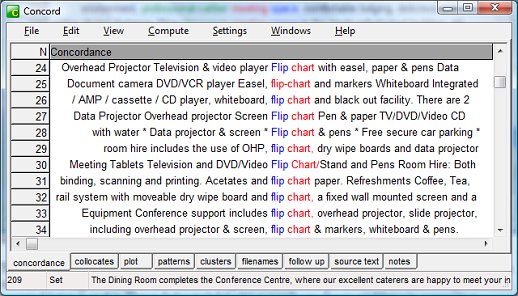
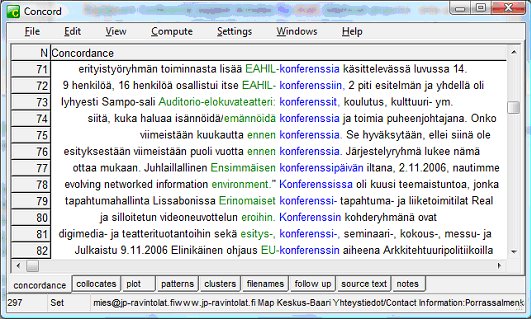
Figure 4 However you soon get lots of ready-made concordance lines, the first of which are visible in Figure 4 - quite useful as such, but you can't "manipulate" them in the same way as you can with a corpus analysis tool. At this point you also have the option of excluding any of the files by unticking the "include in download" checkbox after the document data. For example with the conference + facilities search I got some sites about Italian conference centres that had clearly been translated from Italian into English—so it's handy that those can be deselected so easily. Next you must press the "text files" option in the menu at the top of the page and save the compressed file in a folder of your choice. You will then need to unzip the files into another folder - after which you can try them out with a corpus analysis tool. If you have selected the "combine textfiles" download option (see Figure 7), you will only need to import a single file into your analysis software. With my first query I got a corpus of around 150,000 words, which I then expanded by trying other queries with the Web Concordancer - e.g. conference + data projector. So in less than an hour I had a corpus containing over 500,000 words that was very helpful for checking on terminology usage. In Figures 5 & 6 you can see screenshots showing some of the results from a couple of my searches using WordSmith Tools Version 5 (Scott 2008).
Figure 5
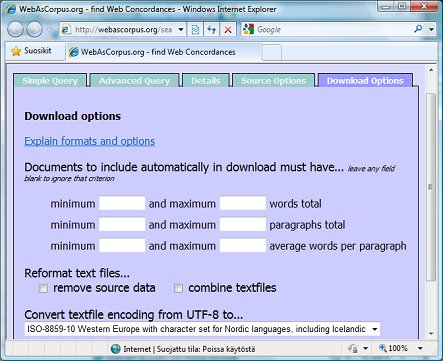
Figure 6 The corpora produced are so-called "dirty corpora", meaning that they haven't been tidied up. Some of my students at the University of Eastern Finland have used Web Concordancer in the past academic year to compile Finnish-language corpora as translation aids or for research purposes and have complained that their corpora tend to be very "messy". For example, Iloniemi (2010) points out that "text files are by default encoded as UTF-8. In WordSmith Tools, Finnish text is displayed incorrectly with this encoding, the preferred encoding being ANSI." Thus the letters å, ä and ö split the words and come out as nonsense graphemes. Iloniemi points out that the same shortcoming may also apply to other languages which include unique characters. However this shortcoming has now been remedied with the latest update of Web Concordancer (24 May, 2010). The new release now enables conversion from UTF-8 into more widely-supported encodings, such as Windows-1252 or ISO-8859-1 for Western European languages. To do this you need to press the "Download Options" tab (see Figure 7).
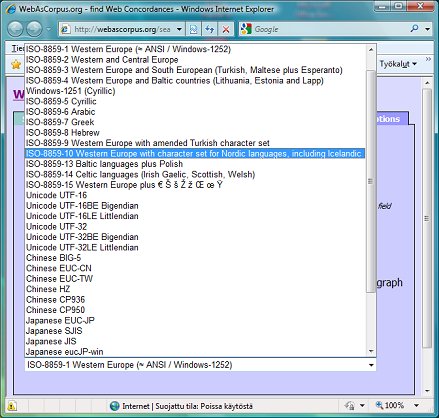
Figure 7 Under "Convert textfile encoding from UTF to..." you can open a pop-up window with over 40 different text-file encodings to choose from (see Figure 8). The download option also includes other useful alternatives for reformatting your text files - these are explained in detail under the "Explain formats and options" link.
Figure 8 In the space of a few minutes, after selecting an appropriate encoding, I compiled a 100,000 word Finnish-language "conference corpus", and as can be seen in figure 9 this produced very clean results.
Figure 9 I strongly recommend those translators who use corpus analysis programs as translation aids to experiment with Web Concordancer. In my opinion it is an invaluable tool for those who need to compile a specialised corpus in a short time.
References Fletcher, William H. (2007-2010). Web as Corpus Web Concordancer. http://webascorpus.org/searchwac.html. Iloniemi, Stiina (2010, unpublished). "Key Word Analyses of Text Corpora as Interpreters' Tools". Pro Seminar paper, University of Eastern Finland. Scott, Mike (2008). WordSmith Tools version 5, Liverpool: Lexical Analysis Software. http://www.lexically.net/wordsmith/index.html Wilkinson, Michael (2005a). "Using a Specialized Corpus to Improve Translation Quality", in Translation Journal, Volume 9, No 3. Online at: http://translationjournal.net/journal/33corpus.htm Wilkinson, Michael (2005b). "Discovering Translation Equivalents in a Tourism Corpus by Means of Fuzzy Searching", in Translation Journal, Volume 9, No 4. Online at: http://translationjournal.net/journal/34corpus.htm Wilkinson, Michael (2006). "Compiling Corpora for use as Translation Resources", in Translation Journal, Volume 10, No 1. Online at: http://translationjournal.net/journal/35corpus.htm Wilkinson, Michael (2007a). "The corpus analysis tool—an under-exploited translation aid" in Kääntäjä 7/2006. Online at: http://www.lexically.net/wordsmith/corpus_linguistics_links/Wilkinson.doc Wilkinson, Michael (2007b).Corpora, Serendipity & Advanced Search Techniques in The Journal of Specialised Translation, 2007. Online at: http://www.jostrans.org/issue07/art_wilkinson.php |
|
|
 uring the past five years I have written several articles discussing some of the ways in which a monolingual target-language corpus can be a useful performance-enhancing resource in translating. Some of these articles are viewable online (see Wilkinson
uring the past five years I have written several articles discussing some of the ways in which a monolingual target-language corpus can be a useful performance-enhancing resource in translating. Some of these articles are viewable online (see Wilkinson